
多読をしていけば自然と英語が読めるようになる。これが期待したい効果なのですが、読めるようになるためには語彙を知っている必要があります。多読で読めるようになるということは自然と語彙が増えてくるということも言えるはずです。
たびたび累積語数ごとの定着語彙数が何語だったかということに触れていましたので、ここでは多読語数と定着語彙数の変化がどうだったか振り返りたいと思います。
定着語彙数とは
単語の数え方が数種あります。
Token 単語1つを1語として数える。同じ単語が複数回登場した場合、回数分加算します。10回登場したら10語となります。running wordとも。多読の1冊の語数を表す総語数とおなじですね。
Types 同じ語は何回登場しても合計1語として数える。10回同じ単語が登場しても1語となる。多読の数え方としてはあまり出番はなさそうです。
Lemma 見出し語ともいわれるようです。複数形、時制、比較級のように形が変化するものはそれらをグループ化したものとして扱い1語として数えます。
word family 1語の意味としては最も広い範囲を持たせています。lemmaに加えて形容詞形、副詞形の活用も同じ1語として数えます。word family で数えると同じ1語として扱う範囲が広がるので、語数は少なくなるということになります。
数え方の違いがあるのでlemmaで数えるか、word familyで数えるかの違いで定着語彙数が変わります。学習者からすると派生形のすべてを理解していなくてもざっくり定着語彙数として数えるので、本当は分かっていない部分がもどかしく感じてきそうです。日本人にはなんとなく定着語彙はlemma数であらわすのが感覚的に近いのかなと思ったりします。
これまで私は定着語彙を測定するのにtestyourvocab.comで行っていました。2022年現在はhttps://preply.com/en/learn/english/test-your-vocabに変わっていました。このサイトの数え方はどれかというとlemmaに近そうですが、自分の変化をつかむなら同じ計測サイトを使い続けるのがいいと思います。100万語の記事でも定着語彙数に触れています。多読履歴 ~100万語 語数毎の感想
累積多読語数と定着語彙数
多読語数と定着語彙数とTOEICの合計点のグラフです。オレンジ色の多読語数の変化はよくわかるのですが、定着語彙数(青色)とTOEIC点数(黄色)に変化がないように見えます。
多読開始前と800万語で比較すると少しは変化しています。
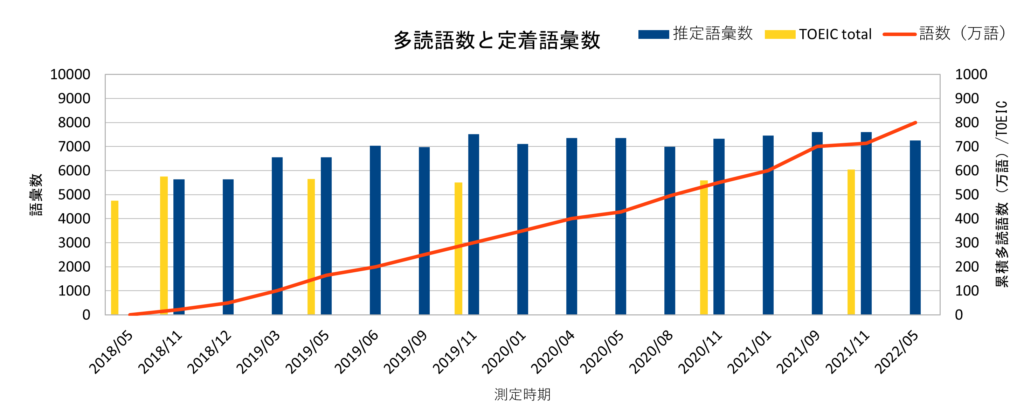
大まかなところで並べていくと
多読語数/定着語彙数/TOEIC合計点数
50万語/5600語/575
100万語/6500語/565
200万語/7000語/-
800万語/7500語605
多読初期は効果を上げていますが、200万語以降は伸び悩んでいます。
語彙制限本(GR)を読むことが多かったので、学習者用に用意された単語にのみ触れることになります。これは遭遇する単語が限られているということですから、見慣れない単語は習得できません。さらに多読の読み方として、良くも悪くもわからない単語は読み飛ばして調べないことも影響していますね。
定着語彙とTOEIC点数は相関があるようで、これまたざっくり1000語あたり100点みたいな感じかなと思っています。知っている語彙数が7500なら750点くらいでしょう ということです。語彙制限本の小説で出現する単語と、TOEICで出現する単語は共通ではないので、純粋に多読だけでは分が悪そうです。ビジネス文書は扱わないですからね。私が思い込んでいる1000語で100点みたいな関係性だと、700点~750点程度とれそうですが、甘くないですね。
洋書や英字新聞をストレスなく読むことが可能になってくるのが10000語程度だと言われているようです。ここまで多読だけで到達するにはまだまだたくさん読む必要がありそうです。
読めなくて、もやがかかったような感覚が晴れていくことを楽しみに続けていこうと思います。


コメント